
In this blog series we’ll be experimenting with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern data lakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT sensor data with idle chatting, we’re curious to find out: will they blend? Want to find out what happens when IBM Watson meets Google News, Hadoop Hive meets Excel, R meets Python, or MS Word meets MongoDB?
Today: Kindle epub meets image JPEG: Will KNIME make peace between the Capulets and the Montagues?

The Challenge
“A plague o’ both your houses! They have made worms’ meat of me!” said Mercutio in Shakespeare’s “Romeo and Juliet” – in which tragedy results from the characters’ inability to communicate effectively. It is worsened by the fact that Romeo and Juliet each come from the feuding “two households”: Romeo a Montague and Juliet, a Capulet.
For this blog article, we decided to take a look at the interaction between the characters in the play by analyzing the script – an epub file – to see just who talks to who. Are the Montagues and Capulets really divided families? Do they really not communicate? To make the results easier to read, we decided to visualize the network as a graph, with each node in the graph representing a character in the play and showing an image of the particular character.
The “Romeo and Juliet” e-book is downloadable for free in a number of formats from the Gutenberg Project web site. For this experiment, we downloaded the epub file. epub is an e-book file format used in many e-reading devices, such as Amazon Kindle for example (for more information about the epub format, check https://en.wikipedia.org/wiki/EPUB).
The images for the characters of the Romeo and Juliet play have been kindly made available by Stadttheater Konstanz in a JPEG format from a live show. JPEG is a commonly used format to store images (for more information about the JPEG format, check https://en.wikipedia.org/wiki/JPEG).
Unlike the Montague and the Capulet families – will epub and JPEG files blend?
Topic. Analyzing the graph structure of the dialogs in Shakespeare’s tragedy “Romeo and Juliet”.
Challenge. Blending epub and JPEG files and combining text mining and network visualization.
Access Mode. epub parser and JPEG reader.
The Experiment
Reading and Processing the Text in the epub file
- The Tika Parser node reads the “Romeo and Juliet” epub file, downloaded from the Gutenberg Project This node integrates the Apache Tika Parser library into KNIME Analytics Platform and can therefore read a very large number of file formats, such as epub, pdf, docx, eml, zip, odp, ppt, and many, many more. The output of the Tika Parser node is a number of String cells containing e-book information, such as title, author, content, etc.
- The “content” column is the column with the full e-book text. It is converted from String into Document type using the Strings to Document node in the wrapped meta-node, “Tag Characters”. The Strings to Document node is part of the KNIME Text Processing extension, which needs to be installed to use the node.
- In this experiment we are not interested in what the characters say but in how they interact with each other, e.g. in how often they talk to each other. The aim is to identify the speaker of each paragraph and tag him or her accordingly. Identifying and tagging characters in the text is the job of the Wildcard Tagger node, still inside the wrapped meta-node, “Tag Characters”. The list of the main characters in the play from the Table Creator node represents the tagging dictionary; we remove all other words to keep only the character names.
- Now, we count the term frequencies and the co-occurrences of all characters using the TF and Term Co-occurrence Counter node. Co-occurrences are normalized pair-wise by creating a pair ID for each unique co-occurrence. Normalization is necessary to count the pairs independently on their occurrence order, e.g. A-B and B-A. This is all handled inside the wrapped meta-node, “Mentions & Interactions”.
- We now set about building the network of interaction among the characters. For each term (=character), the Object Inserter node creates a point in the network. This node is provided by the Network Mining extension. The Object Inserter node also creates an edge between the nodes for each pair of characters. The edges are weighted depending on the number of dialog-based co-occurrences. The term-frequencies of the characters are also inserted into the network as features. This all takes place in the wrapped meta-node, “Build Network”. The output is a network with a node for each character and an edge between characters proportionally thick to the number of interactions between the two characters.
Loading the JPEG image files
- JPEG images of the play’s characters are stored locally on the hard disk of the machine. The URL to the image file for each character is manually inserted in a Table Creator node together with the reference character. The Table Creator node allows the user to manually input data in an Excel-like fashion.
- The list of image URLs feeds the wrapped meta-node, “Load Images”. Inside this wrapped node, an Image Reader (Table) node reads all of the JPEG image files in the list. The Image Reader (Table) node is part of the KNIME Image Processing community extension, which needs to be installed for the node to work.
- The Image Reader (Table) node creates ImagePlus type cells, which have to be converted to regular KNIME image cells to be used for visualization in the network later on. The ImgPlus to PNG Images node, in the Load Images wrapped meta-node, takes care of this task. The output of the meta-node is a table containing the list of character names and the corresponding PNG image.
Blending Text and Images in the Dialog Graph
- It’s time to blend! The character interaction network and the character images can now be blended. This is done by the Multi Feature Inserter node. Each character in the play is assigned a color based on the family affiliation. PNG images and colors are subsequently inserted into the network as features.
- The Network Viewer node finally builds a view of the network, where each node is rendered by the character image, sized by the term (=character) frequency, and border-colored by the family assignment.
The final workflow shown in Figure 1 is available on the KNIME EXAMPLES server under
08_Other_Analytics_Types/01_Text_Processing/18_epub_JPEG_Romeo_Juliet08_Other_Analytics_Types/01_Text_Processing/18_epub_JPEG_Romeo_Juliet*
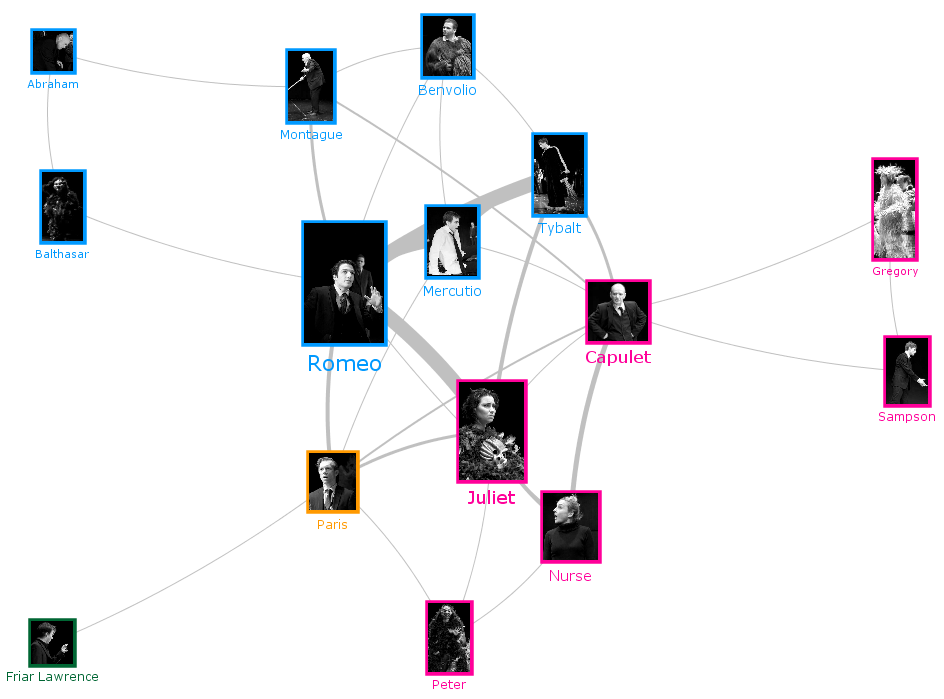
The final graph showing the interaction degree between the different characters of the play is depicted in Figure 2.
(click on the image to see it in full size)
The Results
Yes, they blend!
The graph that comes out of this experiment shows the clear separation between the two families quite impressively. All Montagues in green are on one side; all Capulets in red on the other. The two families only interact with each other through a small number of characters and, not surprisingly, most of the interaction that does take place between the families is between Romeo and Juliet. The separation is so neat that we are tempted to think that Shakespeare used a graph himself to deploy the tragedy dialogs!
In this experiment, we’ve managed to create and visualize the network of interaction between all characters from “Romeo and Juliet”, by parsing the epub text document, reading the JPEG images for all characters, and blending the results into the network.
So, even for this experiment, involving epub and JPEG files, text mining and network visualization, we can conclude that … yes, they blend!
Coming Next…
If you enjoyed this, please share this generously and let us know your ideas for future blends.
We’re looking forward to the next challenge. What about Teradata and the KNIME .table format? Will they blend?
Thank you Stadttheater Konstanz for allowing us use the photos from a production of Romeo and Juliet.
Photographer: Ilja Mess.